
The Future of Compute: NVIDIA's Crown is Slipping
Demand consolidation, changing compute mix, custom silicon, and distributed training will hurt NVIDIA's pole position.


No one has benefitted from the scaling hypothesis quite like NVIDIA. On the back of an AI boom and GPU monopoly, they’ve become the fastest scaling hardware company in history–adding $2T of value in 13 months with SaaS-like margins.
While the H100 generation likely represents peak pricing power (new B200s have lower margins and higher COGS), an immediate lack of alternatives means they’ll continue to print cash.
The open question is long-term (>6yrs) durability1. Hyperscalers (Google, Microsoft, Amazon, and Meta) are aggressively consolidating AI demand to become the dominant consumers of AI accelerators; while developing competitive, highly-credible chip efforts.
Simultaneously, the sheer scale of compute needs has hit limits on capex, power availability, and infrastructure development. This is driving an enormous shift towards distributed, vertically-integrated, and co-optimized systems (chips, racks, networking, cooling, infrastructure software, power) that NVIDIA is ill-prepared to supply.
In this paradigm, NVIDIA can lose with the highest-performing GPUs; the implications will reverberate at every level of the AI stack–from fabs and semiconductors, to infrastructure, clouds, model developers, and the application layer.
Demand Consolidation
NVIDIAs predicament has been driven by hyperscalers' consolidation of AI workloads and accelerator demand–setting the stage for toothier custom silicon and evolving infrastructure requirements.

Already, ~50% of NVIDIA’s datacenter demand is from hyperscalers, the other half comes from a large number of startups, enterprises, VCs, and national consortiums.
That share is set to shrink–the tidal wave of startup spending on GPUs was a transient phenomenon to secure access in a fiercely competitive market. Today, most startups simply don’t have unusual control or infrastructure requirements and are better served by the cloud.
As such, early purchases were ill-fated; this is borne out by low utilization and abysmal ROI’s for small/short term GPU rentals (usually offered by startups that over-provisioned and are forced to rent out at a loss). This is eerily reminiscent of dot com era startups defending costly server hardware as the world moved to the cloud.
More fundamentally, and contrary to early expectations, the model rollout has aggressively consolidated around a few closed source APIs. Even open source and edge models are now the domain of the hyperscalers. Custom, small-midsize models trained with unique data for specific uses have struggled (e.g. Bloomberg GPT). Scaled frontier models can be cheaper while performing and generalizing better – especially with effective RAG and widely available fine-tuning. Thus, the value proposition for most companies training proprietary models is unclear. Going forward, demand from this long tail of buyers looks shaky; considerably consolidating NVIDIA’s revenue base.
Meanwhile, the smaller independent clouds (Coreweave, Lambda, Crusoe, Runpod etc) have very uncertain futures. NVIDIA propped these businesses up with direct investments and preferential GPU allocations in order to drive fragmentation and reduce their reliance on the hyperscalers. Yet, they face long term headwinds without the product variety, infrastructure, and talent to cross-sell and establish lock-in; forcing them to sell commoditized H100 hours. NVIDIA’s production ramp has eroded scarcity and attractive margins baked into initial assumptions, while undermining the “moat” of favorable allocation. These companies are also extremely leveraged on 3rd party demand, and have been relying on GPU-secured debt + heroic fundraising to expand fast enough to reach competitive economies of scale. It’s an open question if this will work, but things look ugly. The effects of lukewarm third party demand are already visible from the high availability and declining GPU/hour costs at small clouds.

Price cuts have reduced costs by 40%+ since last year and show no signs of stopping. This is disastrous for the durability and unit economics of independent clouds. Currently, you can rent GPUs for $1.99/hour. At those prices providers are getting <10% ROE; if prices dip below ~$1.65/hour they will be eating losses. This pain may be obfuscated2 by long depreciation schedules (4+ year useful lives for an A100?) but will come to bite eventually. When it does, NVIDIA will have few alternative outlets for demand.
In contrast, external hyperscale cloud demand has grown rapidly. It’s so high that developers (even OpenAI!) are facing chronic shortages with monthlong lead times. This is bolstered by internal demand, with 50-70% of total compute going to frontier training runs and inference for major launches (e.g. Copilot, Gemini, Meta AI). Despite $20b+ each in yearly capex, all the major clouds are at capacity. With their scale and infrastructure experience, the “big three” cloud providers are best positioned to amortize depreciation and downtime costs while offering superior flexibility, security, and reliability. As a result, AI service margins are high and customer trust is strong.
These are the same structural advantages that drove the original transition to the cloud from on-prem. Hyperscalers will keep pressing and are poised to increase market share for AI workloads. As a result, we’ve already begun to see a major revenue consolidation for NVIDIA: in their Q2 earnings, a single cloud provider accounted for 29% of quarterly data center (a $3.9b purchase or ~130k H100s).
In light of this, NVIDIA is almost akin to an automotive component supplier; deriving most of their revenue from four customers with deep coffers, talent, and competitive ambitions. They have no way to reverse this trend. Now, they must gamble the business on their most competent competitors' chip efforts.
Competing Silicon
NVIDIA’s dominance for powering parallel AI/ML workloads was a manageable equilibrium when GPU spending was in the hundreds of millions. This is no longer the case; Microsoft added $10B/quarter in incremental AI spend last year. Capex is now >25% of gross profit at some hyperscalers with GPUs making up half of infrastructure spend and ~80% of datacenter TCO. Also, unlike software, inference is core to the marginal cost structure.

As future training runs ($5B+) bump against spending limitations, customization, and capital efficiency will be paramount to maximally scaling compute, training the best models, and staying competitive. Simply ignoring NVIDIA and their margin stacking is no longer an option.
While independent NVIDIA alternatives have struggled, the hyperscalers have a successful track record of substituting and designing out key chip suppliers. Meta designed NVIDIA out (!) for some of their largest DLRM workloads with their ASICs, and Google did the same for key video encoding workloads from YouTube. Amazon replaced hypervisors with Nitro back in 2012 and a huge volume of intel CPUs with Graviton.
Hyperscale customers present extreme risk3 as they focus relentlessly on cost reduction, substitution, and internal chips efforts. In doing so, they (and key design partners like Marvell, Broadcom, Astera, Arista and AIchip) bring to bear massive amounts of capital and engineering talent to actively undermine NVIDIA’s core business.

Google is a prime example of this. Their legacy workloads (search, ads, translate) made them one of the largest consumers of accelerated computing and ML inference. As such, they’ve been working on AI accelerators (TPUs) in-house since 2013. While development now follows multi-year timelines, v1 only took 15 months from kickoff to deployment – with limited budget, talent, and an architecture from a 1978 paper. Given this, TPU performance is astonishing. They’re cheaper than H100s for inference and competitive for large training runs–Gemini-Ultra, a GPT-4 Class, frontier model was trained exclusively on TPU V4 clusters (these are 2 generations old!).
Large enterprises have switched as well. Midjourney trained exclusively on TPUs and Anthropic uses v5e for inference. Most recently, Apple chose to train its SOTA 3B parameter local model on a mix of TPU V4 and V5p instead of NVIDIA.
The pace of improvement isn’t slowing. TPUs are in their 6th generation and investment has accelerated. The newest gen (Trillium) has doubled energy efficiency and HBM capacity while more than tripling peak performance. Google is also iterating on its software stack. They’ve transitioned away from TensorFlow to JAX – which handles compilation and low level deployment optimization. While slower than CUDA on GPUs, JAX is an increasingly viable cross-platform alternative. This is the result of improving support (e.g. libraries like Equinox), better scalability, speedups from compiling into XLA, as well as native support for autodiff and JIT compilation.
Critically, TPUs + JAX have been so effective that they’ve almost entirely replaced NVIDIA GPUs for Google’s internal AI Workloads. This includes all of Deepmind (!), Gemini training + inference, as well as YouTube DLRM. Employees literally can’t remember the last time they used NVIDIA. Nearly all remaining demand is for external GCP clients, but even here TPUs are aggressively ramping to serve more workloads and further constrain NVIDIA spend.

It’s not just Google, Amazon is ramping up chip development–powered by its 2015 acquisition of Annapurna Labs4. They recently launched second generation Inferentia and new Trainium chips, with spending projected to ramp up to $2.5B by 2026. While Gen 1 ran Alexa’s backend, Gen 2 (with more HBM and bandwidth) is focused on LLM price/performance optimization. It’s been accompanied by the Neuron SDK – a custom compiler that completely replaces CUDA. It provides low level control and is compatible with Torch, Jax, and TensorFlow – developers particularly like its performance analysis tooling. Combined, this has proved a viable NVIDIA substitute for inference and large model training workloads. Anthropic now uses Amazon as their primary compute vendor; moving frontier model training and inference workloads to custom hardware in lieu of NVIDIA. The two are even co-developing future generations of Amazon hardware, informed by Anthropic.
Microsoft is similarly focused on ramping up internal chip development efforts5. 300 employees have drawn on past chip experience (Xbox) and a close partnership with AMD (eventually Marvell by ‘25-’26) to launch their first-gen Maia 100 accelerator and associated Cobalt 100 CPU (an ARM based, Ampere replacement). The Maia accelerator is impressive; in raw FLOPS it’s competitive with H100s, but it’s been constrained by HBM bandwidth (likely on account of their pre-LLM design and optimization for CNNs).
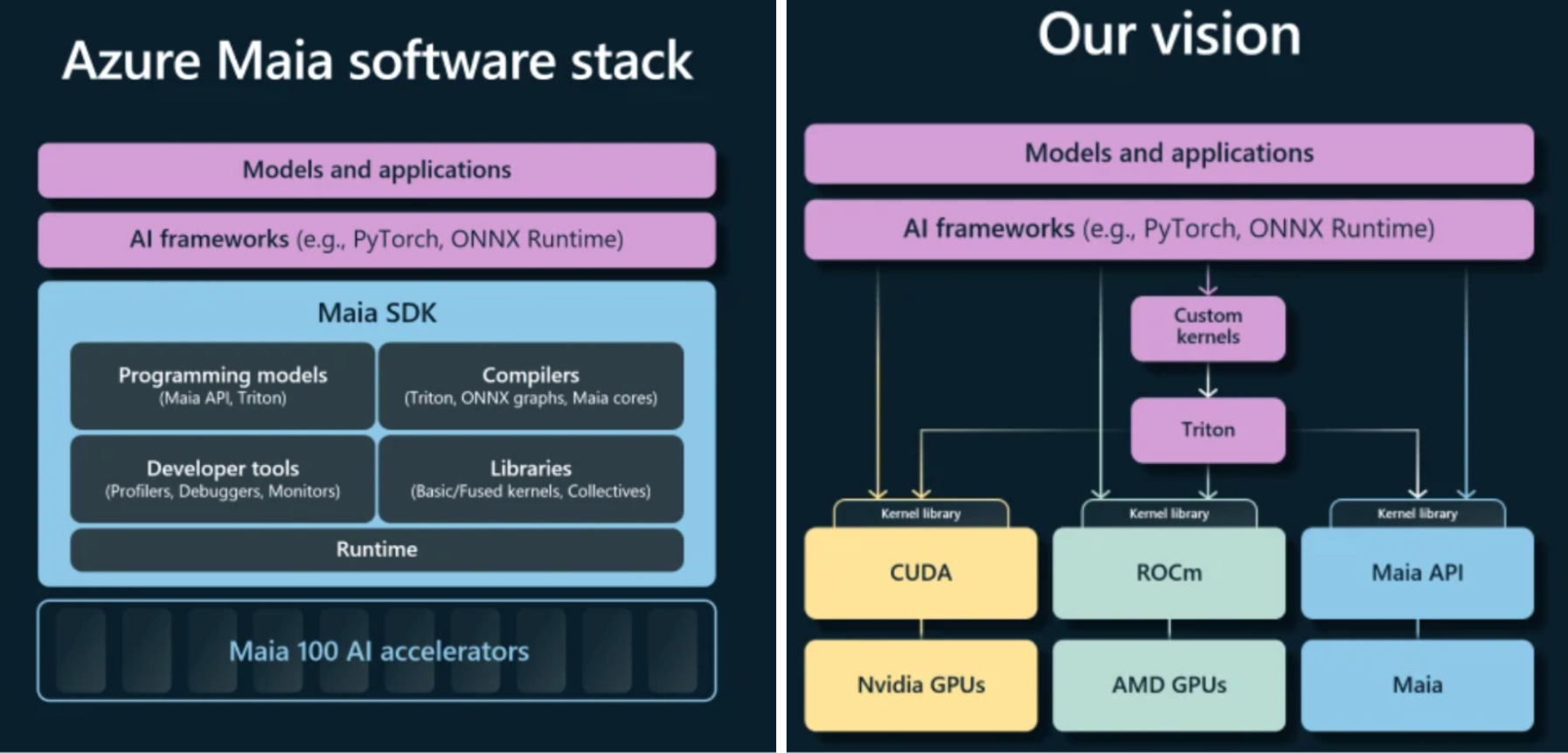
On the software side, Microsoft launched the Maia SDK – a Pytorch compatible compiler that leans on OpenAI’s Triton framework to replace CUDA6. Triton is both fairly efficient and very abstracted from underlying hardware, making it generalizable and highly legible to an ML engineer. Microsoft is pushing to use Triton to standardize and simplify custom kernel development. They’ve also already rolled out a new data format (MX v1.0) to standardize quantization across providers. This would make custom and 3rd party chips seamlessly interoperable and give devs complete portability; in effect commoditizing NVIDIA. Maia is very early, but has been tested in production; serving inference for Bing Chat (now Copilot) and Github Copilot. Future use cases will include 3rd party inference (OAI), training Microsoft’s GPT4 level internal model (MAI-1), and serving Azure customers.
Even Meta is stepping into the custom silicon game and serving meaningful production workloads. Early Meta chips were optimized to serve ranking, advertising, and recommendation workloads (DLRM) for Instagram and Reels. This has changed with the launch of their second-gen MTIA chips and a custom built software stack to support it. These V2 chips are designed to serve AI inference applications for Meta AI characters/chat on Instagram and WhatsApp; they have already been deployed to data centers and are serving use cases in production. Meta is intent on expanding the scope of these chips particularly for synthetic data generation. Llama 3.1 relied on this for supervised fine tuning and distillation to pretrain smaller models. In Zuckerberg’s view, immense inference capacity is a priority for future frontier model training. While Meta still purchases NVIDIA, the direction they’re moving is clear.

The shift to custom silicon is especially telling because it’s happening in a market that should reinforce NVIDIAs moat. Current AI workloads are skewed towards training, even at Microsoft training is ~60% of compute demand. In theory, this should have limited the viability of custom silicon, as training is memory bound and sensitive to footprint constraints. As AI adoption accelerates, productization matures, and the revenue hole is filled7, the balance will shift to inference; increasing pressure on NVIDIA. By 2025, 70% of GPU hours will be spent on inference where custom silicon is especially competitive. Even to date, inference commoditization has been extremely aggressive. In many cases (especially for mid size models) last gen A100s offer better performance/$ than H100s, and AMD has quietly become a more competitive substitute8. In the longer term it’s even possible that CPU-based inference is optimal, particularly for small models.
Ultimately, hyperscalers' successes with developing and deploying custom chips (particularly Google’s) is deeply worrying for NVIDIA. Hyperscalers have a long history of designing out component vendors, in a world of increasing consolidation this may be existential. Many of the most competitive chip efforts were started with different mandates over a decade ago–well before the massive wave of AI demand. While accelerator design cycles are long, it’s an eminently solvable problem that simply requires commitment, capital, and scale.
The Distributed Scale Problem
When discussing competing chip efforts, some will rebut that on a per-chip basis NVIDIAs upcoming B100 will be much faster (delivering the performance of 3 Trillium TPUs). This may be true, but it illustrates a more important issue; per-chip performance doesn’t matter; NVIDIA can make the highest-performing GPUs on earth and lose.
Hyperscalers have the ability to vertically integrate while leveraging scale and specialization to make distributed systems that are cheaper and more performant in aggregate. For a platform agnostic supplier like NVIDIA, this is a structurally difficult trend to compete with or adapt to.

This is the result of a broader trend; with the breakdown of dennard scaling and SRAM logic shrinking, returns to transistor miniaturization have decreased and new node costs have been skyrocketing. Hardware gains (density, performance, and cost) increasingly come from system technology co-optimization; the intelligent design of interconnect, chiplets, cooling, power, racks, and data centers. Much of this has been enabled by advanced packaging (e.g. chiplets, increased on-package HBM) and larger substrates. However, even more gains have come from a conscious effort by datacenter operators, suppliers, and system integrators to tailor designs for hyperscale needs. We’ve just begun to see optimization at this layer in light of changing requirements for AI servers and data centers.

Microsoft's data center design is an example of this. They are planning their own telecom fiber network and rolling out new ColorZ pluggable optical transceivers + DSPs to support long distance (<80km) data transmission – effectively increasing peak cluster performance by connecting data centers. To support the huge data flows, Microsoft is planning developments of in package, and eventually on chip optics for switches and transceivers. Current racks with Maia chips have even more vertical integration. They use custom power distribution, high-bandwidth ethernet protocols, and dedicated in-rack “sidekicks” to enable closed loop liquid cooling; increasing chip density while decreasing interconnect requirements and cost. Importantly, these servers integrate into existing Azure datacenter infrastructure, allowing for dynamic power optimization, easier management, and greater compute capacity in existing footprints; a requirement for scaling training runs in a world limited by build outs.
Google understands this deeply. They have intentionally moved away from big chips to swarms of smaller, cheaper ASICs with deep interconnects. At the rack level, all TPUs have identical configurations – unburdened by the need to support different environments. They also have fewer server boards that are integrated in the rack. This increases shelf density and further reduces the complexity of hardware deployment. Google also uses ICI as opposed to NVLink enabling them to connect slices of 64 TPUs very cheaply over passive copper.

Unlike Nvidia, however, Google also customizes significantly at and beyond the data center level. TPUs are designed to run in pods of 4096 chips using custom optical switches (Apollo) in lieu of normal electronic packet switches, greatly reducing power-consumption and downtime compared to NVIDIA. This is possible because across the data center, TPUs use a unique torus-shaped network topology, as opposed to Clos; improving latency and locality. Combined with proprietary cloud networking hardware and software (Jupiter), massive clusters of TPUs can be organized across data centers. This is how Google data centers provide performance/TCO that is nearly 30% lower than competitors (primarily on account of reduced chip cost, downtime, and infra spend).
More importantly, in conjunction with smaller batch sizes, data verification tricks, and advanced partitioning, it means Google can train frontier models like Gemini Pro 1.5 over multiple connected data centers.
This minimizes power/size requirements for future training (and likely search + synthetic data) infrastructure. It also greatly improves hardware modularity and extends the useful life of older chips/build outs as they can run alongside cutting-edge clusters in the future to train frontier models. Other hyperscalers are going in this direction as well; Meta trained Llama 3 across two data centers and Microsoft is connecting clusters across the country for OpenAI. Infrastructure will become increasingly distributed as labs move away from synchronous training via hierarchical gradient descent. Meta, OpenAI, and Google are all actively researching ways to train separate model copies and merge branches back together–enabling truly asynchronous distributed training.

This is a massive advantage; distributed infrastructure is the only way we continue scaling and count new OOMs. Right now compute is the biggest limitation for pushing frontier models; Mark Zuckerberg has explicitly said that building out ultra-large data centers is a binding constraint. Multi-datacenter training runs enable the use of smaller, interconnected data centers. This reduces cost and increases throughput, but it also confers substantial benefits for quickly conducting and scaling infrastructure build outs. With smaller data centers, it is far easier to create designs, procure land rights/permitting, EIA approval, suppliers/GCs and build out transmission + voltage transformers. Connected clusters could also help overcome power constraints on a grid that's at capacity. Vanishingly few utilities have enough excess capacity to keep scaling; this is doubly true in prime locations with clean energy (required for hyperscalers given net-zero commitments). The issue is so acute that Microsoft reopened 3-Mile Island (835MW) and pre-purchased fusion power from Helion; AWS purchased a 960MW nuclear plant. Regardless, individual data centers will quickly hit size limits (e.g. a 10GW cluster would be ~1% of installed US power).

However, connected campuses and networked cross-regional clusters may be able to move away from single endpoints and draw power from multiple utilities and power sources. Interestingly, If you look at a map of hyperscale data-centers and cross reference it with power zones, you’ll see many nearby datacenters are already served by different utilities. Currently we’re limited to in-region data centers using ethernet (<40km), but plans are being made to leverage telecom fiber and connect datacenters as far as ~500km away. Microsoft is already digging and has spent over $10 billion with fiber network providers like Lumen. While this will take a few years to deploy, it will provide 1-5Pbit of bandwidth and <1sec weight exchanges; enough to make multi-region training viable.

These regionally distributed training systems will keep scaling going and become the norm, enabling cheaper, faster infrastructure build outs while pushing peak power/compute across a single run (x-xxGWs). While distributed systems create some opportunities for nontraditional but well capitalized players, infrastructure expertise matters and it’s imperative for hyperscalers to scale along the frontier to train better models. The key long-term difference is that training will occur on “small” networked campuses of x00MW-xGW datacenters as opposed to monolithic xxGW class data centers.
Such a world makes it extremely difficult for NVIDIA to compete on a performance or cost basis. Their lunch will be eaten as there’s no room for unspecialized platforms. They can’t deeply integrate with a cloud or customize hardware without designing out subscale customers– which would further consolidate demand, subsidize competitors and commoditize their product. This is the innovator's dilemma that makes NVIDIA ill-suited to serve cross cluster or exascale use cases. The evidence of this is already reflected in surprising weaknesses when building massive, maximally performant systems.

For instance, NVIDIA’s Infiniband networking infrastructure is clearly not meant to support 100K+ GPU clusters. By design, every GPU is only connected to a single NIC, and every packet has to be delivered in the same order. Since models are so large and weights are distributed, a single failed NIC, GPU, or optical transceiver can take down an entire server, forcing data to be retransmitted (this compounds as new racks make nodes larger). Even with frequent checkpointing this drags down MFU by multiple percentage points. Moreover, while Nvidia is driving the transition to 800 Gbps networking (useful for all customers), they’ve been caught flat footed for a massive, hyperscale-led shift in datacom. We are likely to see increasing use of pluggable ZR transceivers to support the ultra-high bandwidth fiber connections needed to connect data centers. As part of this we may also get new DSPs and supporting telecom hardware (Amplifiers, Multiplexers, Transponders etc)–undermining NVIDIAs networking stack while benefiting providers like Coherent, Lumentum, Inphi, Cisco, and Nokia.
Unfortunately for NVIDIA, blind spots extend to the infrastructure software stack. One of the most pressing issues is fault tolerance – key for ensuring reliability and high utilization when dealing with many points of failure in a training run. For subscale customers this isn’t a problem, but with really large cluster sizes NVIDIAs network design and hardware choices provide no built in protection. Despite this, NVIDIA still doesn't have a compelling proprietary library to handle fault tolerant training; subscale clients rely on open source frameworks. The major hyperscalers now rely on more robust internal solutions. For instance, Google uses proprietary software called Pathways; it does a fantastic job of covering more edge cases and types of faults than other solutions (While being able to operate flexibly with synchronous and asynchronous data flows). Pathways is also very good at detecting and fixing nearly invisible GPU memory issues that slip past ECC; NVIDIAs diagnostic tool (DCGM) is considerably less reliable. NVIDIA also struggles to provide competitive partitioning and cluster management software. Their BaseCommand system (built on Kubernetes) is designed to be cross platform and work with heterogeneous systems. However, once again, hyperscalers have better proprietary, integrated solutions like Borg (Google, also the basis of Kubernetes) and Singularity (Microsoft) which better handle scaled VM/container management, transparent migration, and GPU workload scheduling/management. Google even has a custom sharder called MegaScaler for synchronously partitioning workloads across TPU pods within and beyond a single campus.
Hyperscalers' core advantage is their vertical integration across the semiconductor, infrastructure, and model layers–which enables improved system level understanding, observability, co-optimization and failure analysis. NVIDIA has made some strides with Blackwell and GB200 servers to confront structural issues stemming from this.

On the hardware level, they installed rack wide copper-connected backplanes and required liquid cooling to improve density, energy efficiency and TCO. They’re also rolling out a new ethernet-based, datacenter-scale networking solution called Spectrum-X (both the absolute and relative success to Broadcom will be worth watching closely). On the software side, they’re aggressively updating their DCGM software and pushing a dedicated engine for reliability, availability and serviceability (RAS). This is meant to help mitigate persistent NIC/Infiniband failures by using sensor level chip data to preemptively alert operators to failures.
However, all things considered, this isn’t enough. As discussed, better versions of nearly all key infrastructure software exist internally, and on the hardware side NVIDIA is behind the curve; they will struggle to adapt to massive change whereas the hyperscalers have been scaled and vertically integrated for a long time. Cooling is a great example of this. While NVIDIA just mandated liquid, Google did so back in 2018 with TPU v3 deployments. Today, they use 2x less water/kWh than Microsoft’s NVIDIA datacenters and have a PUE (power usage effectiveness) of 1.1, compared to >1.4. This means NVIDIA’s decision to keep small customers happy and drag their feet on integration cost them 30% of effective power and 50% of footprint at every hyperscale data center!
No doubt, NVIDIA is aware of this and they are trying to push up the value chain (DGX Cloud, NGC etc). Yet current efforts betray a narrow scope of vision; primarily optimizing at the data center level when the future is moving towards large campuses and clouds. While Jensen has demonstrated a willingness to play for the future (see the prescient Mellanox acquisition), NVIDIA today faces unprecedented secular challenges that have killed a long line of high-flying predecessors. Uneasy lies the head that wears the crown.
Thanks to: Lachy Groom, Jack Whitaker, Lauren Reeder, Gavin Uberti, Divyahans Gupta, Philip Clark, John Luttig, Tyler Cowen, Shahin Farshchi, Jannik Schilling, Bridget Harris, Harry Elliott, Luke Farritor, Jacob Rintamaki, Joe Semrai, Coen Armstrong, Trevor Chow, and Catherine Wu
Disclaimer: All views are exclusively my own and do not represent those of any of past or present employers. Everything in this article is based on public information. I hold no positions in Nvidia (NVDA). I am long Marvell (MRVL), Google (GOOG), Broadcom (AVGO), Vertiv (VRT), Micron (MU), Fabrinet (FN), Coherent (COHR), Talen Energy (TLN), ACM Research (ACMR), and Credo (CRDO)
NVIDIA has created a medium-term moat simply by booking out advanced packaging and cutting-edge wafer capacity. TSMC is constrained by CoWoS and EUV lithography; all capacity is filled through 2026 and conservative investments for the upcoming N2 node will redouble shortages in 2028. Combined with long design cycles for new silicon, this will help NVIDIA maintain significant share through 2030. While this does shut out competitors, it isn’t indicative of chips bottlenecking compute scaling (currently infrastructure buildouts are a larger issue).
It’s possible 3rd party clouds can hang on and benefit from future GPU shortages. However, this would be a paradigm where independent clouds rely on NVIDIAs generosity and have their ROE swing wildly based on GPU availability - contracting/losing money in times of abundance and growing in shortages. This is not the outcome investors are playing for and long-term challenges remain WRT establishing lock-in and tepid 3rd party demand.
It’s worth mentioning that hyperscalers and their partners are not the only competitors to NVIDIA. A host of well-capitalized startups are going after the AI accelerator market, oftentimes with very specific approaches to design and differentiation. Details remain light and things remain early (tape-outs take a long time!), but some notable players include:
Etched - Transformer-specific ASICs enabling extremely high throughput and large batch sizes
Cerebras (partnered w/ G42 in Abu Dhabi) - Wafer-scale chips with massive SRAM capacity and interconnect for improved memory bandwidth/scaling. IPO now pending.
Sambanova - Integrated AI systems with flexible scaling, improved memory bandwidth (3-tiered, DRAM-based caching), and efficient data movement (RDA instead of ISA).
Groq - Ultra-low latency chips with a fully deterministic VLIW architecture and model weights stored across SRAM.
MatX - Focus on high throughput and exascale use cases (>10^22 FLOPS for training, millions of users for inference).
Lightmatter - Photonic chips (Envise) that use optical waveguides instead of wires and direct fiber attach for interconnect (this also works with 3rd party chips)
Tenstorrent - RISC-V based AI-CPUs focused on inference workloads, led by chip-legend Jim Keller.
Rain AI - Focus on using RISC-V, in-memory compute, and custom BF16 quantization to deliver improved power efficiency w/ minimal accuracy loss, backed by Sam Altman.
Tiny - Building an alternative instruction set to ROCm in service of longer-term chip efforts.
Many of these hardware startups are pushing up the value chain by (sometimes exclusively) directly serving their chips on the cloud (e.g. Groq, Cerebras). Many others that originally started in chips ended up abandoning hardware entirely; often on account of technical difficulty, but also because of the exponentially increasing costs of leading-edge nodes (particularly without sufficient volume).
There are also some Chinese chip efforts that are competing with NVIDIA, notably:
Huawei - Produces the Ascend lineup of chips (910B, 910C). These chips claim competitive performance with A100s. They have garnered major orders from BAT companies as well as Bytedance (100k+ chip orders).
Alibaba - Their chip division (T-head) produces the Hanguang 800 for AI inference workloads. This is a ~5yr old chip and they have been actively purchasing Huawei chips.
Baidu - Their chip division (“Kunlun”) last produced the Kunlun II in 2021. This was used in the datacenter but also for autonomous vehicles.
Cambricon - Cambricon makes the MLU370 line of accelerators. They have faced substantial losses, layoffs, and the withdrawal of strategic investors (e.g. Alibaba).
Biren - Launched the BR104 and BR100 line of GPUs. They have struggled and both founders recently resigned.
Hyperscalers have a long history of making and integrating acquisitions when it’s highly strategic or accretive (e.g. Microsoft/Fungible for networking and Google/Motorola for mobile IP). Chip companies are no different (e.g. Google/Agnilux, and arguably Microsoft/Xbox). As hyperscalers build out chip teams, strategic acquisitions for talent, IP and reduced time to tape outs shouldn’t be dismissed. The world is awash in potential targets; Sambanova, Ampere (likely w/ Oracle as a purchaser), Altera (maybe all of Intel!), or even divisions of Nuvia/Qualcomm stand out as interesting.
Microsoft’s chip effort is separate from OpenAI. Unlike the Amazon/Anthropic relationship both OAI and Microsoft are developing custom chips. Publicly, very little reliable reporting has occurred with regards to OAI’s chip effort. That said, the OAI chip effort is serious. They have invested aggressively and been on a hiring spree; mostly recruiting good ex-Google TPU engineers and some strategic policy people (e.g. Chris Lehane). Acquisition rumors have been floated to accelerate timelines as well as a Broadcom partnership (much like Google and Meta currently have). There have also been reports of international data center deployments across Japan, The North Sea, and The Middle East on the scale of hundreds of billions of dollars and 5-7GW of power (Notably, Microsoft has invested in deployments in the Middle East through G42 and Cerebras).
When discussing NVIDIA, CUDA is often cited as an almost mythical moat. In reality, importance varies greatly by customer. For hyperscalers, spending billions on custom chip efforts and large scale workloads, it’s not a meaningful barrier. They have deep benches of engineering talent and have a long history of creating internal tooling that better fulfills their needs. We’ve already seen hyperscalers create and switch to these alternatives. Google JAX has been the most effective so far (displacing all internal NVIDIA/CUDA use). However, that success should worry NVIDIA bulls; especially given the active development of Amazon Neuron, Microsoft Maia, Huawei CANN, Facebook's MTIA stack. Moreover, two of the three big research labs (Anthropic and Deepmind) have bypassed NVIDIA GPUs and by extension CUDA for their core operations; OpenAI is attempting to switch to Triton as well. The transition away from CUDA at hyperscalers for internal workloads has already happened. On the other side of things are startups and the “long tail” of demand. Some of this is proprietary but a lot goes through the major clouds. Here CUDA can be useful, but if one believes the consolidation story, major training workloads will happen at hyperscalers. Thus, external cloud demand should primarily be inference/fine tuning that doesn't require developers to leave Torch. Even today, most external infra teams are small and simply work in Torch. Hyperscalers realize this and Microsoft in particular has been using Triton + Pytorch 2.0 to create a framework where underlying hardware (ASICs, GPUs) is interchangeable. This has major advantages for the cloud and would replace CUDA while letting devs stay in Torch. It would also benefit developers by making designs less sensitive to specific memory architectures of certain GPUs.
Baked into this analysis is the assumption that the revenue hole fills. It’s possible this does not happen (because large scale AI use cases fail to materialize and spending is unproductive). In this world the outcome for NVIDIA is the same but the prognosis is different. Hyperscalers would be wary of sinking large sums into proprietary chip efforts and NVIDIA may maintain a moat in accelerated computing, by definition however this would be a much less valuable market than NVIDIA bulls are pricing in. The flip side is more interesting. True disciples of the bitter lesson would expect demand to accelerate well beyond projections and create shortages. Yet, being short the scaling laws is not the same as being short NVIDIA. While it might provide breathing room (a rising tide lifts all boats) the long term story actually seems worse. A scaling-pilled world would drive further demand consolidation, create stronger substitution incentives for hyperscalers, and increase the relative importance of supporting infrastructure/software.
AMD performance has greatly improved as developers ported vLLM to ROCm and optimized Pytorch integrations, quantization, and attention implementations. They’re a particularly compelling choice for inference cost reduction. Depending on the chip and use case, AMD is achieving parity with NVIDIA. MosaicML even demonstrated out of the box, small-model training with MI250s; achieving per-GPU throughput that was within 80% of A100s. Oracle just launched broad availability of AMDs new MI300x, and while work is ongoing, early results are promising (particularly for latency sensitive applications). At Microsoft, the MI300x is being used for internal workloads and aggressively prioritized for support and deployment to Azure customers; primarily to drive cost reductions. As software and kernels improve (or are replaced with Triton) performance will continue to scale and underlying hardware advantages (HBM quantity and throughput) will better come through. Moreover, they have been aggressively scaling production and increasing TSMC allocations to meet demand, overcome shortages and eat into NVIDIAs revenue share (2025 is when AMDs revenue should really inflect)